How helpful is Hattie & Donoghue's model of learning? Part 2: The meta analyses
Jun 18, 2017
To help us better understand how we learn, John Hattie & Gregory Donoghue propose a new conceptual model of learning. I've already written about my concerns with the metaphor of depth in Part 1. In this post I want to explore what his meta analyses reveal about the best approaches to take with students at different stages in the journey from novice to expert.Inputs
The first layer of Hattie & Donoghue's model is termed 'inputs' or, what children bring to the process of learning. These are grouped into three areas dubbed skill, will and thrill.
The most important individual differences between students is the quality and quantity of what they know. This varies enormously between students depending on what culturally specific information they have encountered over their lives. Hattie summaries this as 'prior achievement' and gives it an effect size of 0.77. Perhaps the second most important fact determining children's probability of successfully learning is their working memory capacity. This varies much less than prior knowledge; we all have fragile, constrained working memory capacities with must people only able to handle 4 'chunks' of information at any one time. (Cowan, 2010) Hattie gives this an effect size of 0.68.
Alongside this two 'inputs', Hattie & Donoghue suggest that students need various dispositions to be able to learn effectively. This table summarises their findings of what's important:
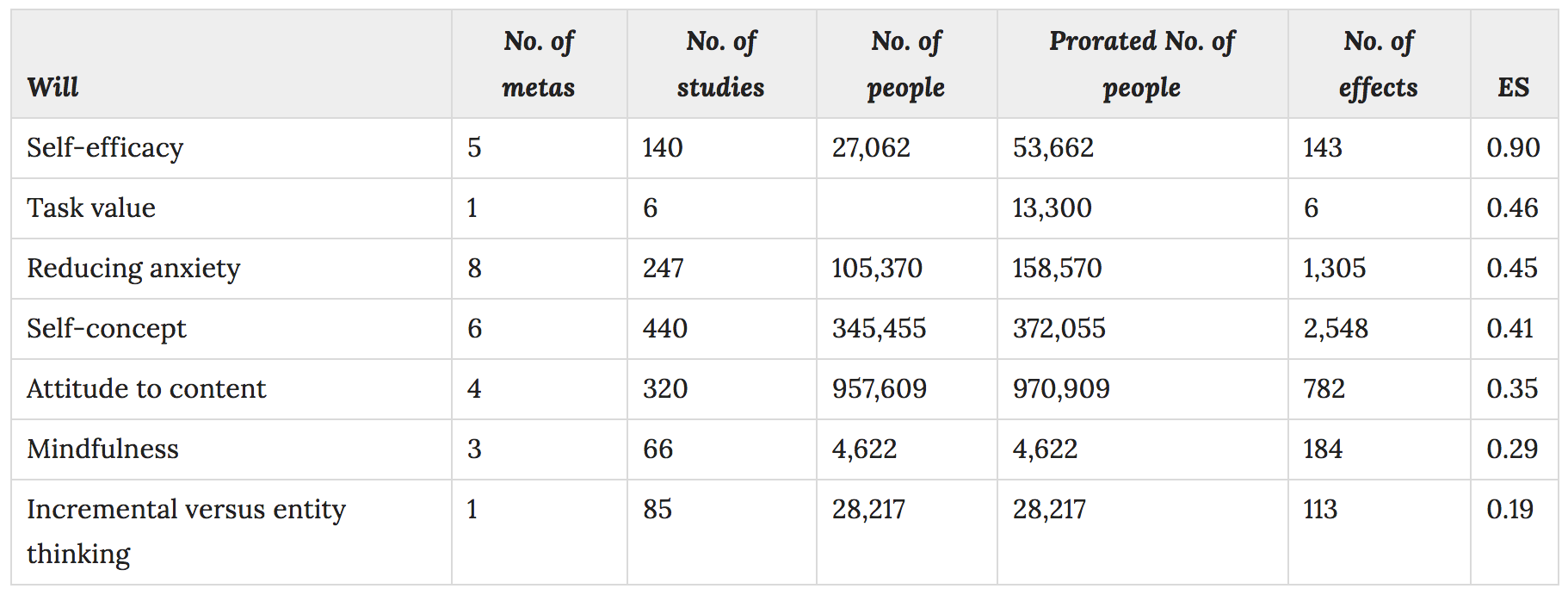
Self-efficacy - our belief in our own capability - is apparently twice as important as any other disposition. This is, perhaps, unsurprising. For most people, experience of success leads to an increased belief in our ability to be successful in the future. The problem though is that this is, I suspect, almost entirely domain-specific. Doing well in maths might lead to improved self-efficacy in maths lessons but is unlikely to make a difference to performance in unrelated domains. My hunch is that our self-efficacy is governed by our prior knowledge and attainment which will, in turn, be correlated with working memory capacity.
It's worth noting that having an incremental (growth) mindset as opposed to an entity (fixed) mindset appears to make little difference. This is in line with the critique of growth mindset I've offered here.
The final area of 'inputs' is centred around our motivation to learn. This, to me, seems to be the most conceptually confused area as you can perhaps see from this summary:
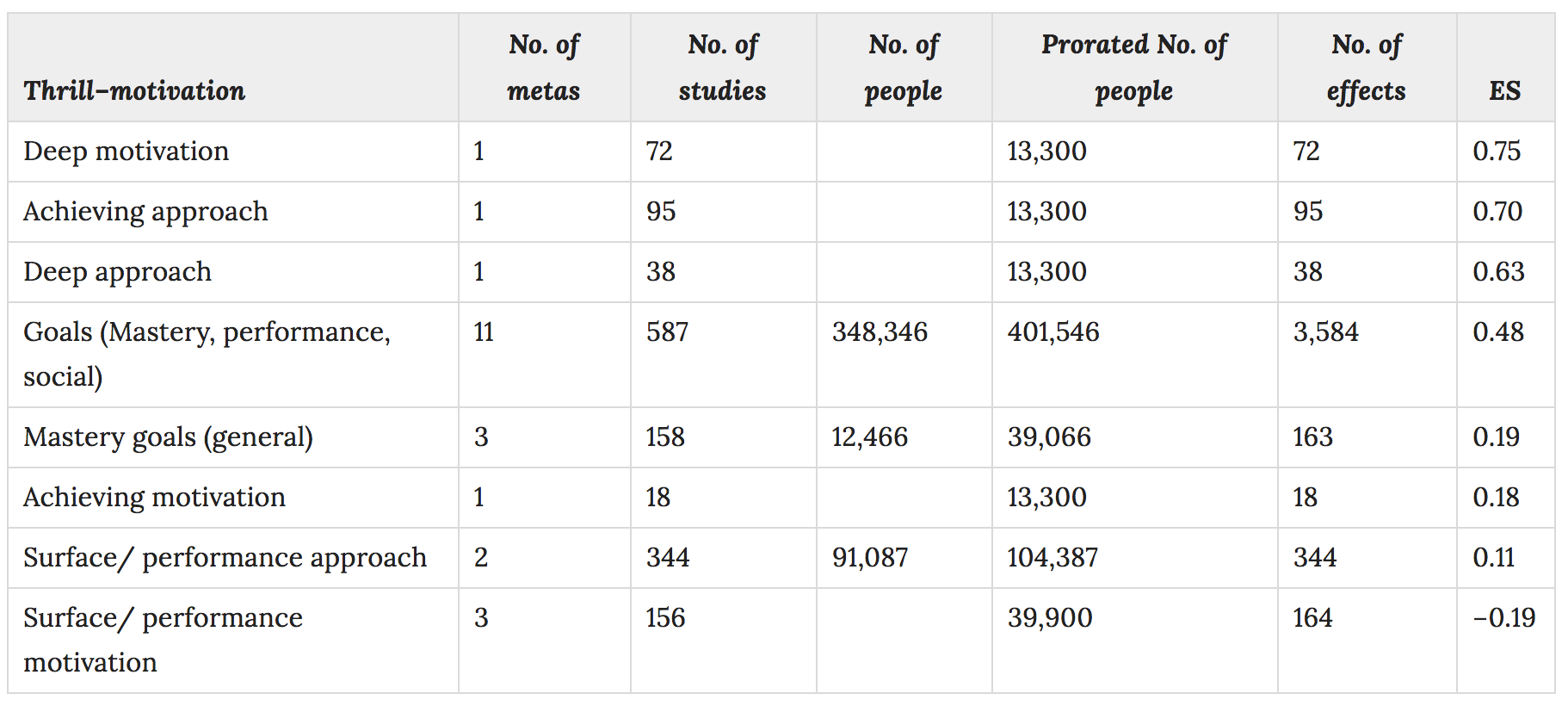
To make sense of this, we have unpick what's meant by 'deep motivation'. Hattie and Donoghue are of little help here:
Having a surface or performance approach motivation (learning to merely pass tests or for short-term gains) or mastery goals is not conducive to maximising learning, whereas having a deep or achieving approach or motivation is helpful.This is another example of how unhelpful the metaphor of depth can be. Obviously, short term goals focussed merely on passing a test are less likely to lead to expertise than a desire to comprehensively master a subject, but this is trivially true. To really make sense of these effect sizes I'd like to take a look at the meta analysis for 'deep motivation' to see what the 72 studies cited are actually researching.
Environment
The next layer of the model is the environment in which children learn. What's most interesting, and perhaps not that much of a surprise, is that environment factors seem to matter less than what students bring with them:
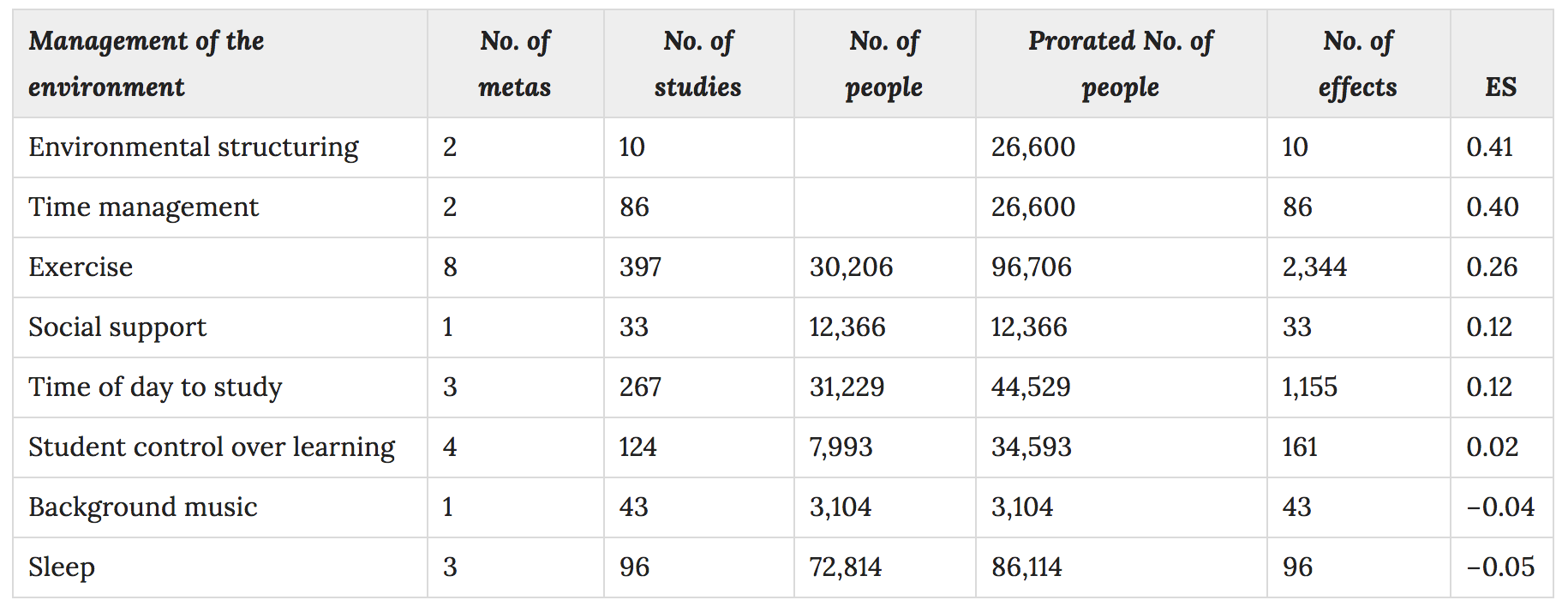
More important, is the extent to which students understand what it is they are being asked to learn. This is grouped under the heading 'success criteria'.
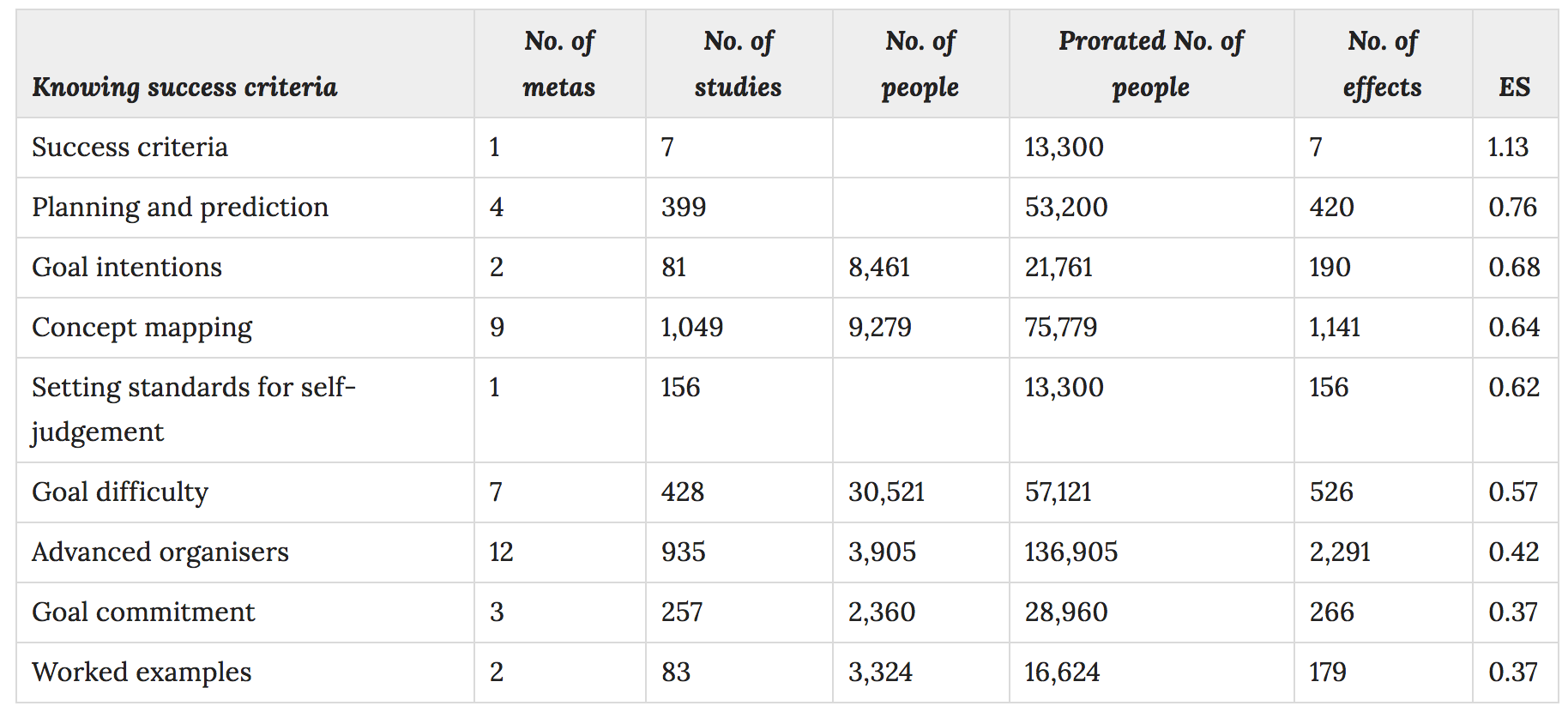
There's a lot of nuance missing from this table, some of which Hattie & Donoghue attempt to fill in. For instance, they say, "When a teacher provides students with a concept map, for example, the effect on student learning is very low; but in contrast, when teachers work together with students to develop a concept map, the effect is much higher." This seems to suggest the importance of the Bananarama Principle: it's not what you do, it the way that you do it. Of particular interest to me is the relatively low effect size of worked examples compared to the improbably large effect size attributed to 'success criteria'. The suggestion that giving success criteria has an effect size of over a whole standard deviation is based on a single meta analysis of just 7 studies. If it's true then giving success criteria is one of the most powerful interventions a teacher can make, but before we get too excited we'd need to drill into the primary research to see what specifically is being suggested.
Surface or deep?
The next phase of the model is the most interesting. Here Hattie & Donoghue attempt to show at what stage in students' learning should various strategies be implemented. It turns out that different strategies work well at one stage and are a mistake at others. They divide this process into five stages:
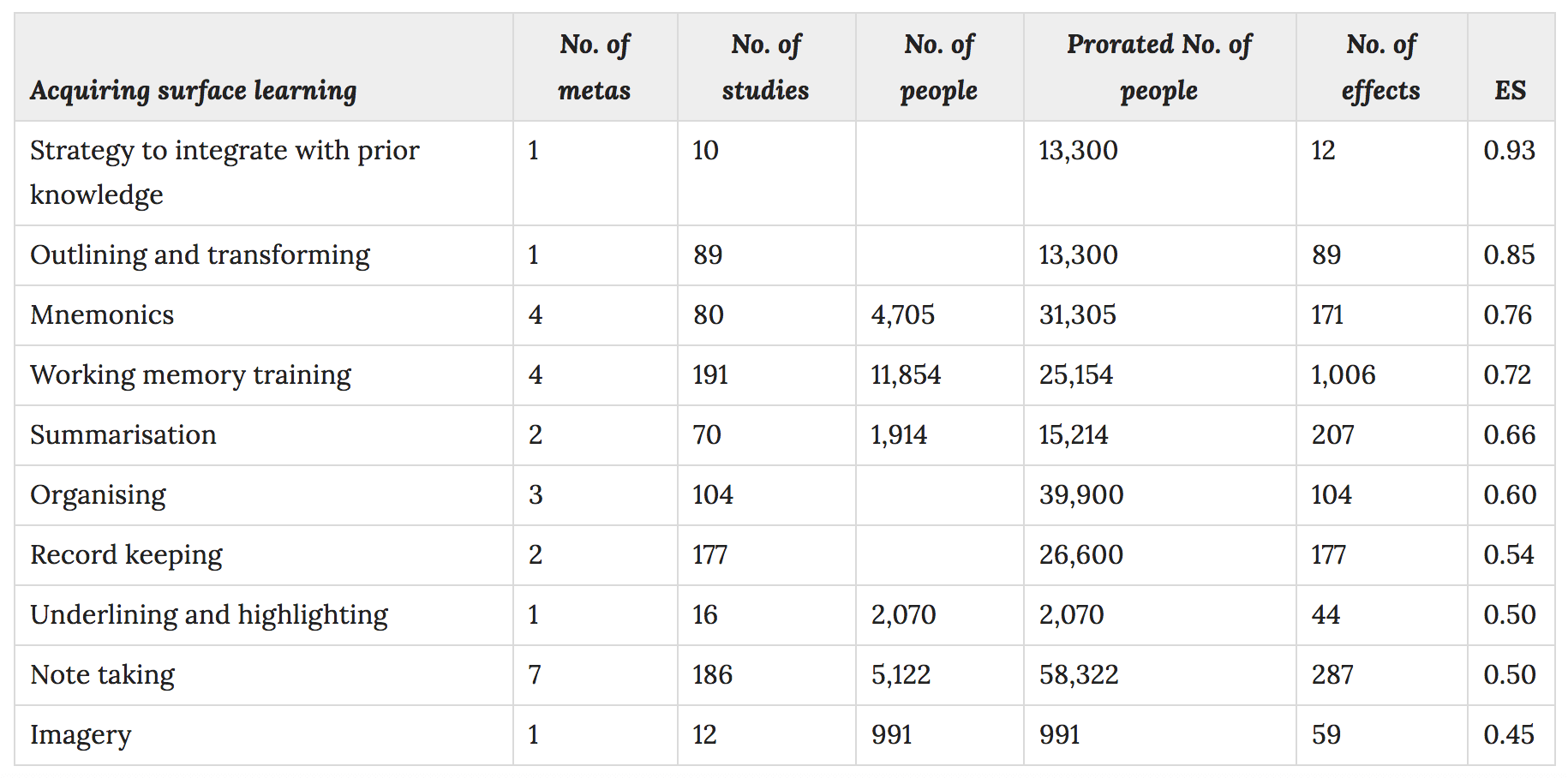
1. Acquiring surface learning
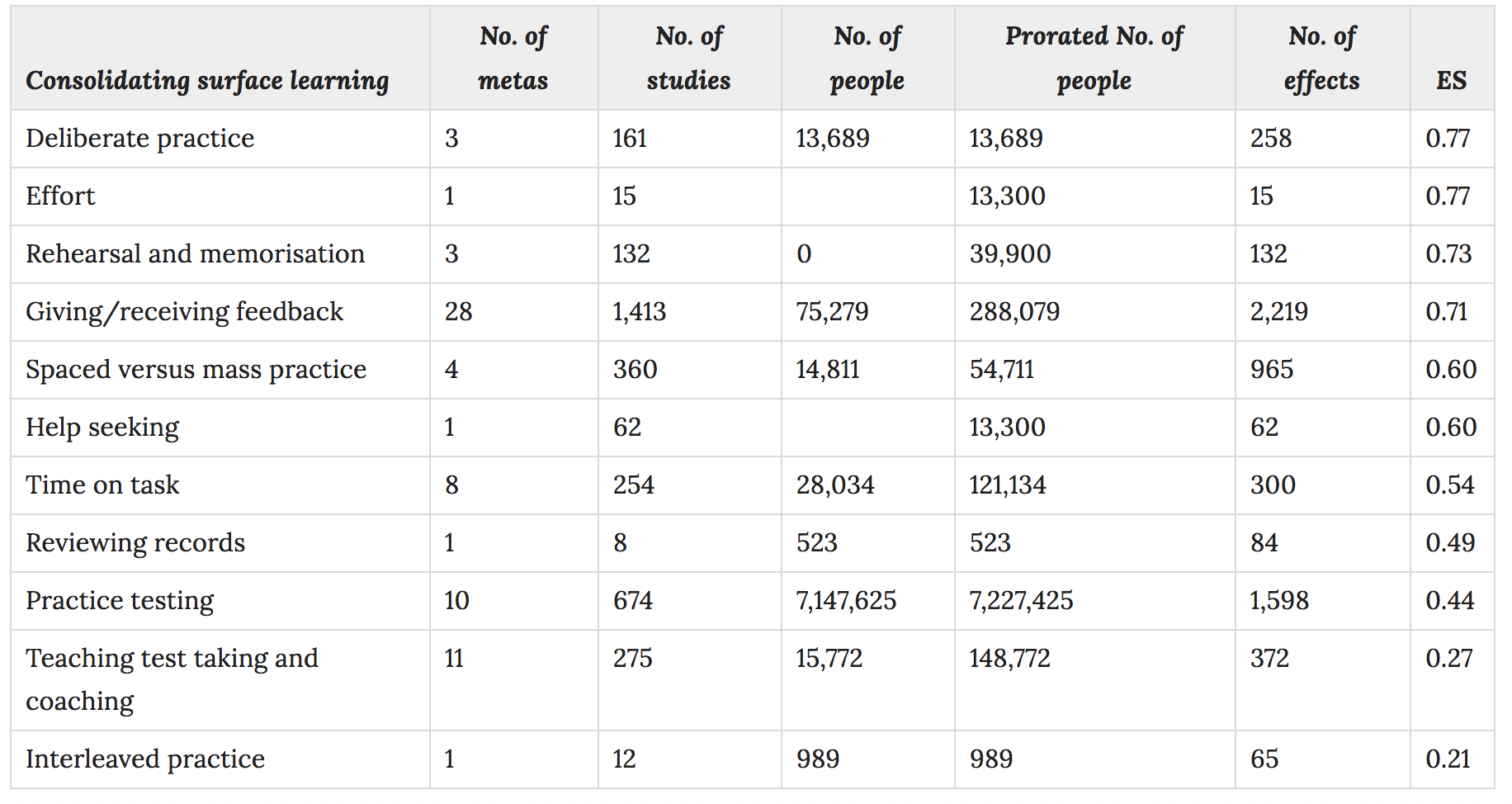
2. Consolidating surface learning
3. Acquiring deeper learning

4. Consolidating deeper learning

5. Transfer

The great pity of all this is that the same interventions are not evaluated at different stages of the learning process. For instance, what are we to make of the fining that deliberate practice has an effect size of 0.77 at the 'consolidating surface learning' stage but is not evaluated at later stages. The clear finding from the research into developing expertise is that deliberate practice is the strategy that makes the most difference in increasing expert performance.
There are a few other findings that seem to contradict established fields of scientific enquiry. For instance, we're told working memory training has an effect size of 0.72 at the 'acquiring surface learning' stage but as there is no reliable evidence that working memory capacity can be increased except in very narrow domains, this seems highly unlikely.
Other suggestions seem more like post-hoc rationalisations than sensible suggestions for changing teachers' practice. For instance, 'seeing patterns to new situations' is a definite hallmark of expertise but it's a function of knowing lots about a specific domain. It's obvious that if students can see the deep structure of problems and how this can be transferred from one problem to another that they have achieved transfer, but you can't just teach students to do this. It's a function of having acquired lots and lots of 'surface' knowledge. Hattie & Donoghue say, "It is learning to detect differences and similarities that is the key that leads to transfer of learning." Again, this is trivially true. Of much more importance is the fact that in order to do this you need a well-developed schematic knowledge and lots of practice at thinking in the domain in which you hope to become an expert.
To sum up, I have three broad areas of concern:
- Unless we can see how the various strategies compare at different stages of learning, we have no real way of evaluating their relative effectiveness.
- Unless we can pick through the primary research, we have no way of knowing whether Hattie & Donoghue's conclusions are warranted.
- If the surface→deep→transfer model is unhelpful and be better replaced with an novice→expert model, would we need to group the strategies differently?
In my next post I'll discuss Hattie & Donoghue's conclusions and suggest a possible improvement of their model of learning.
The Learning Spy Substack is a sharp, provocative dispatch from the front lines of education, where ideas are tested, myths are challenged, and nothing is taken for granted.
Join me on Substack