The Unit of Education
Jan 08, 2015
If you cannot measure it, you cannot improve it.A lot of education research is an attempt to measure the effects of teaching (or teachers) on learning (or pupils.) But is this actually possible?
Lord Kelvin
Let’s first think about measurement in a very practical sense. Schools limit admission based on a sometimes very strict catchment area – if you want to make sure that your children attend a particular school you need to live within the catchment. For some very oversubscribed schools this can be a radius of less than a mile. If I measure the distance between my front door and the school I would like my daughter to attend I need some agreed unit of measurement for my reckoning to mean anything; the local authority won’t be interested in, “It’s quite close.”
In order to work out how close, we agree on a measurement system and measuring devices which enable us to define the criterion of being within or outside the catchment area. However, when it comes to measuring concepts such as progress, or learning, or teacher effectiveness, things become much more complicated. We still feel the urge to convert things into numbers, but often there is little agreement. We think we’re being precise when bandying about such numbers, but really they’re entirely arbitrary
Remember the scene from the film Spinal Tap where guitarist Nigel Tufnel proudly demonstrates a custom-made amplifier whose volume control is marked from zero to eleven, instead of the usual zero to ten? Nigel is convinced the numbering increases the volume of the amp, "It's one louder". When asked why the ten setting is not simply set to be louder, Nigel is clearly confused. Patiently he explains, "These go to eleven."
https://www.youtube.com/watch?v=KOO5S4vxi0o
And how often have you heard an over-enthusiastic school leader exhort teachers to give 110%?
Now I say all this because it strikes me that we have no agreed measure of impact or progress in education. Because there is such a heavy emphasis on ‘progress’ it has become desirable to find ways of measuring it. One such measure, which has been widely gobbled up, is the effect size (ES). This is a way of quantifying the magnitude of the difference between two groups, allowing us to move beyond simply stating that an intervention works to being able to the more sophisticated consideration of how well it works compared to other interventions. John Hattie has done much to popularise the effect size, analysing a thousands of studies by imposing the same unit of measurement on them. This begs the question, does the effect size give an accurate and valid measure of difference?
In order to this question we need to know what an ES actually corresponds to i.e. What is the unit of education? An ES of 0 means that the average treatment participant outperformed 50% of the control participants. An effect size of 0.7 means that the average participant will have outperformed the average control group member by 70%. The baseline is that a year’s teaching should translate into a year’s progress and that any intervention that produces an ES of 0.4 is worthy of consideration.[i] [See Dylan Wiliam's correction below.]
Australian education professor, John Hattie went about aggregating the effects of thousands of research studies to tell us how great an impact we could attribute to the various interventions and factors at play in classrooms.
This is what he found:
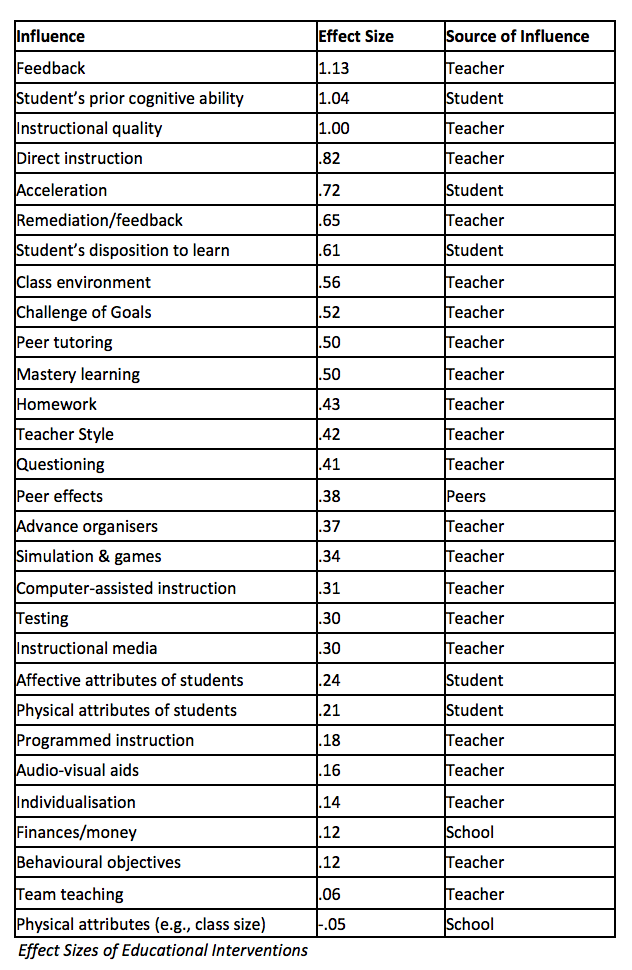 So now we know. Giving feedback is ace, questioning is barely worth it, and adjusting class size is pointless. You might well have a problem with some of those findings but let’s accept them for the time being.
So now we know. Giving feedback is ace, questioning is barely worth it, and adjusting class size is pointless. You might well have a problem with some of those findings but let’s accept them for the time being.Hattie then goes on to make this claim:
An effect-size of d=1.0 indicates an increase of one standard deviation... A one standard deviation increase is typically associated with advancing children's achievement by two to three years, improving the rate of learning by 50%, or a correlation between some variable (e.g., amount of homework) and achievement of approximately r=0.50. When implementing a new program, an effect-size of 1.0 would mean that, on average, students receiving that treatment would exceed 84% of students not receiving that treatment.[ii]Really? So if ‘feedback is given an effect size of 1.13 are we really supposed to believe that pupils given feedback would learn over 50% more than those who are not? Is that controlled against groups of pupils who were given no feedback at all? Seems unlikely, doesn’t it? And what does the finding that Direct Instruction has an ES of .82 mean? I doubt forcing passionate advocates of discovery learning to use DI would have any such effect.
At this point it might be worth unpicking what we mean by meta-analysis. The term refers to statistical methods for contrasting and combining results from different studies, in the hope of identifying patterns, sources of disagreement, or other interesting relationships that may come to light from poring over the entrails of qualitative research.
The way meta-analyses are conducted in education has been nicked from clinicians. But in medicine it’s a lot easier to agree on what’s being measured: are you still alive a year after being discharge from hospital? Lumping the results from different education studies together tricks us into assuming different outcome measures are equally sensitive to what teachers do. Or to put it another way, that there is a standard unit of education. Now, if we don’t even agree what education is for, being unable to measure the success of different interventions in a meaningful way is a bit of stumbling block.
And then to make matters worse, it turns out the concept of the ‘effect size’ itself may be wrong. There are at least three problems with effect sizes. Dylan Wiliam points to two problems: the range of children studies and the issue of 'sensitivity to instruction' and Ollie Orange suggests another: the problem of time.
Firstly, the range of achievement of pupils studied influences effect sizes.
An increase of 5 points on a test where the population standard deviation is 10 points would result in an effect size of 0.5 standard deviations. However, the same intervention when administered only to the upper half of the same population, provided that it was equally effective for all students, would result in an effect size of over 0.8 standard deviations, due to the reduced variance of the subsample.[iii]Older children will show less improvement than younger children because they've already done a lot of learning and improvements are now much more incremental. If studies are comparing the effects of inventions with six year olds and sixteen year olds and are claiming to measure a common impact, their findings will be garbage.
The second problem is how do we know there’s any impact at all? To see any kind of effect we usually rely on measuring pupils’ performance in some kind of test. But assessments vary greatly in the extent to which they measure the things that educational processes change. Those who design standardized tests put a lot of effort into ensuring their sensitivity to instruction is minimised. A test can be made more reliable by getting rid of questions which don’t differentiate between pupils – so if all pupils tend to get particular questions right or wrong then they’re of limited use. But this process changes the nature of tests: it may be that questions which teachers are good at teaching are replaced with those they’re not so good at teaching. This might be fair enough except how then can we possibly hope to measure the extent to which pupils’ performance is influenced by particular teacher interventions?
The effects of sensitivity to instruction are a big deal. For instance, it’s been claimed that one-to-one tutorial instruction is more effective than average group-based instruction by two standard deviations.[iv] This is hardly credible. In standardised tests one year’s progress for an average student is equivalent to one-fourth of a standard deviation, so one year’s individual tuition would have to equal 9 years of average group-based instruction! Hmm? The point is, the time lag between teaching and testing appears to the biggest factor in determining sensitivity to instruction. Outcome measures used in different studies are unlikely to have the same view of sensitivity to instruction.
The third problem is one of the time it takes to teach. Let's say we decide to compare two teachers using identical teaching methods, teaching two classes of children of exactly the same age. We test both classes at the start of a unit of work and at the end to see what impact the teaching has had. If children in both classes made identical gains, what would such a comparison tell us? Superficially it appears we're comparing like with like but if it takes the first class one week to learn the material and the second class two weeks to learn the material, then any such comparison is meaningless. The Effect Size would calculate both teachers as equally effective, but if the results are the same, one class learned twice as fast as the other. Any proper unit of eduction would need to account for the time it takes for students to learn a thing.
In Hattie’s meta analysis there’s little attempt to control for these problems. This doesn’t mean we shouldn’t trust that those things he puts at the top of his list don’t have greater impact than those at the bottom, but it does mean we should think twice before bandying about effect sizes as evidence of potential impact.
When numerical values are assigned to teaching we're very easily are taken in. The effects of teaching and learning are far too complex to be easily understood, but numbers are easily understood: this one's bigger than that. This leads to pseudo-accuracy and makes us believe there are easy solutions to difficult problems. Few teachers (and I certainly include myself here) are statistically literate enough to properly interrogate this approach. The table of effect sizes with its beguilingly accurate seeming numbers has been a comfort: someone has relieved us of having to think. But can we rely on these figures? Do they really tell us anything useful about how we should adjust our classroom practice?
A mix of healthy scepticism and a willingness to think is always needed when looking at research evidence, but assigning numerical values and establishing a hierarchy of interventions is probably less than useful.
References
[i] Robert Coe, It's the Effect Size, Stupid: What effect size is and why it is important
[ii] John Hattie, Visible Learning
[iii] Dylan Wiliam “An integrative summary of the research literature and implications for a new theory of formative assessment.” In H. L. Andrade & G. J. Cizek (Eds.), Handbook of formative assessment (2010)
[iv] Benjamin S Bloom, “The Search for Methods of Group Instruction as Effective as One-to-One Tutoring”, Educational Leadership (1984)
The Learning Spy Substack is a sharp, provocative dispatch from the front lines of education, where ideas are tested, myths are challenged, and nothing is taken for granted.
Join me on Substack