It's the bell curve, stupid!
Jun 10, 2015
Like an ultimate fact without any cause, the individual outcome of a measurement is, however, in general not comprehended by laws. This must necessarily be the case. Wolfgang Pauli
 This leads to all sorts of misunderstandings and mistakes. Well-intentioned school leaders leap on the top scoring inventions and confidently conclude, "Yay! If we do feedback and metacognition our students will make a whole 16 months of extra progress!" Sadly, it's all a bit more complicated than that.
The reported impact for an intervention is an average. Research on each of the different interventions is aggregated to show a normal distribution of effects. So for an effect size of 0.8 we might get a distribution a bit like this:
This leads to all sorts of misunderstandings and mistakes. Well-intentioned school leaders leap on the top scoring inventions and confidently conclude, "Yay! If we do feedback and metacognition our students will make a whole 16 months of extra progress!" Sadly, it's all a bit more complicated than that.
The reported impact for an intervention is an average. Research on each of the different interventions is aggregated to show a normal distribution of effects. So for an effect size of 0.8 we might get a distribution a bit like this: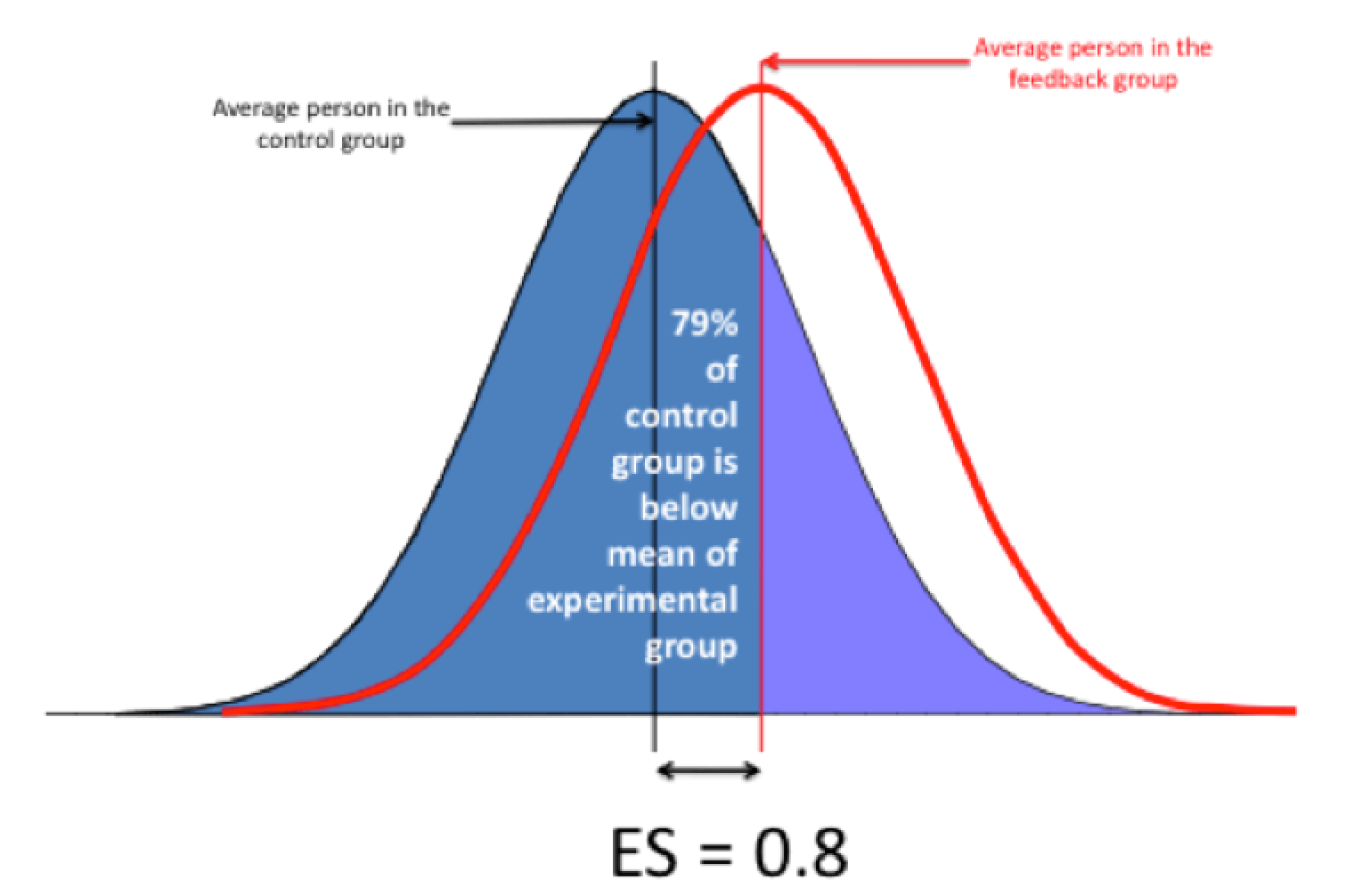 So, what does this actually tell us? Well, for the headline figures to be meaningful, we really have to look at the shape of the distribution to see just how good our implementation of an intervention would have to be to get an average effect. Consider this example of one of the 'best bets' like feedback or metacognition:
So, what does this actually tell us? Well, for the headline figures to be meaningful, we really have to look at the shape of the distribution to see just how good our implementation of an intervention would have to be to get an average effect. Consider this example of one of the 'best bets' like feedback or metacognition:
 The wide distribution tells us that some studies will have shown the intervention to have fairly poor impact whereas other studies will have demonstrated extraordinary impact. The area shaded in mauve indicates the sort of impact we would have to aim at in order to get anywhere near the +8 months reported by the Toolkit. In a best bet, our intervention only has to be of average effectiveness in order to reap rewards. This helps to explain why the possible negative impacts of feedback are so powerful. As Hattie says, "Feedback is one of the most powerful influences on learning and achievement, but this impact can be either positive or negative."
However, if we turn our attention to interventions with good, but more modest impacts, like, say, digital technology or small group tuition, both reported as providing +4 months progress, the bell curve will look more like this:
The wide distribution tells us that some studies will have shown the intervention to have fairly poor impact whereas other studies will have demonstrated extraordinary impact. The area shaded in mauve indicates the sort of impact we would have to aim at in order to get anywhere near the +8 months reported by the Toolkit. In a best bet, our intervention only has to be of average effectiveness in order to reap rewards. This helps to explain why the possible negative impacts of feedback are so powerful. As Hattie says, "Feedback is one of the most powerful influences on learning and achievement, but this impact can be either positive or negative."
However, if we turn our attention to interventions with good, but more modest impacts, like, say, digital technology or small group tuition, both reported as providing +4 months progress, the bell curve will look more like this:
 What this demonstrates is that our intervention will have to slightly better than the average implementation of this approach in order to be as worthwhile as we might want. And if our intervention goes badly, there's actually a risk it might make a negative impact on progress.
Which brings us to some of the riskier approaches. Somewhat controversially, the EEF reports that there's fairly robust evidence (indicated by the 3 padlocks) that implementing Learning Styles offers +2 months of progress for a very modest outlay of time and resources. That's not too shabby, is it?
What this demonstrates is that our intervention will have to slightly better than the average implementation of this approach in order to be as worthwhile as we might want. And if our intervention goes badly, there's actually a risk it might make a negative impact on progress.
Which brings us to some of the riskier approaches. Somewhat controversially, the EEF reports that there's fairly robust evidence (indicated by the 3 padlocks) that implementing Learning Styles offers +2 months of progress for a very modest outlay of time and resources. That's not too shabby, is it?
 But surely Learning Styles has been thoroughly debunked and dismissed? What's going on? Let's have a look at the bell curve:
But surely Learning Styles has been thoroughly debunked and dismissed? What's going on? Let's have a look at the bell curve:
 What this tells us is that it may actually be possible to implement Learning Styles in a way that benefits pupils' progress. Maybe your school will be one of the lucky few. But the average effects are fairly negligible and probably not worth even modest outlays. And there, on the left-hand side of the distribution is why implementing a strategy like Learning Styles is so risky: 50% of the studies will show impacts of less than +2 months. And an unacceptably high number of studies will have reported negative impacts will actually impede pupil's progress.
I should add that the bell curves shown in this post are from Steve's presentation and don't actually represent the actual distributions for the particular inventions I've discussed in this post. Apparently feedback has one of the widest distributions of effects whereas other interventions have much sharper peaks with less leeway either side. Dylan Wiliam provided this distribution of the 607 effect sizes of feedback found by Kluger & DeNisi in their seminal 1996 meta-analysis.
What this tells us is that it may actually be possible to implement Learning Styles in a way that benefits pupils' progress. Maybe your school will be one of the lucky few. But the average effects are fairly negligible and probably not worth even modest outlays. And there, on the left-hand side of the distribution is why implementing a strategy like Learning Styles is so risky: 50% of the studies will show impacts of less than +2 months. And an unacceptably high number of studies will have reported negative impacts will actually impede pupil's progress.
I should add that the bell curves shown in this post are from Steve's presentation and don't actually represent the actual distributions for the particular inventions I've discussed in this post. Apparently feedback has one of the widest distributions of effects whereas other interventions have much sharper peaks with less leeway either side. Dylan Wiliam provided this distribution of the 607 effect sizes of feedback found by Kluger & DeNisi in their seminal 1996 meta-analysis.
 As you can see, the distribution is anything but normal with the effects averaging around 0.41, but 38% of the effect sizes were negative. If this is anything to go by it tells us our attempts to give students feedback must be very carefully thought out indeed. Doing feedback averagely well looks to be a waste of time! There are, however, some very intriguing outliers which is where further research and experimentation ought to be focussed
After listening to the presentation, I asked Steve if the actual distributions are available. He explained that when the Toolkit was being put together that it was decided that displaying the bell curves would be too complicated and would just over-burden poor, unsophisticated teachers. Nonsense!
I don't know about you, but I said then and still think this is nonsense! Maybe it might be too complex for some but then, as I used to tell my students, nobody ever rises to low expectations. Hell, I'm only an English teacher! If I can get it, so can you! If the information was available, some of us would make an effort to understand it. If the information isn't available then we guarantee a lowest common denominator is achieved. (This is very much the problem with differentiating resources by the way.) Happily Steve agreed and committed himself to doing something about it. I saw him again yesterday and lo! he's in the process of making the bell curves available on the EEF website. Hopefully soon, we'll be able to click through from the headline figures and actually examine the shape of the curve for any intervention we're considering implementing. This is a minor triumph for teachers and might be a small step along the road to greater professionalism.
As you can see, the distribution is anything but normal with the effects averaging around 0.41, but 38% of the effect sizes were negative. If this is anything to go by it tells us our attempts to give students feedback must be very carefully thought out indeed. Doing feedback averagely well looks to be a waste of time! There are, however, some very intriguing outliers which is where further research and experimentation ought to be focussed
After listening to the presentation, I asked Steve if the actual distributions are available. He explained that when the Toolkit was being put together that it was decided that displaying the bell curves would be too complicated and would just over-burden poor, unsophisticated teachers. Nonsense!
I don't know about you, but I said then and still think this is nonsense! Maybe it might be too complex for some but then, as I used to tell my students, nobody ever rises to low expectations. Hell, I'm only an English teacher! If I can get it, so can you! If the information was available, some of us would make an effort to understand it. If the information isn't available then we guarantee a lowest common denominator is achieved. (This is very much the problem with differentiating resources by the way.) Happily Steve agreed and committed himself to doing something about it. I saw him again yesterday and lo! he's in the process of making the bell curves available on the EEF website. Hopefully soon, we'll be able to click through from the headline figures and actually examine the shape of the curve for any intervention we're considering implementing. This is a minor triumph for teachers and might be a small step along the road to greater professionalism.
The Learning Spy Substack is a sharp, provocative dispatch from the front lines of education, where ideas are tested, myths are challenged, and nothing is taken for granted.
Join me on Substack