How helpful is Hattie & Donoghue's model of learning? Part 1: The problem with depth
Jun 17, 2017
I saw John Hattie speak recently at a conference on his latest re-imagining of his Visible Learning work. He was an excellent speaker and charming company. I was particularly flattered that he asked me to sign his copy of my What if... book. After he'd finished his presentation he asked me what I thought and I said I'd have to go away and have a think. This is an attempt to tease out a response.Broadly, I found myself in agreement. Hattie makes the astute point that the 400 learning strategies identified in his most recent meta analysis cannot be directly compared; some are effective at some stages and for some reasons but not for others. This makes a great deal of sense and it fits well with the idea of the expertise reversal effect that finds discovery approaches tend to backfire with novices but start to become much effective with experts.
The model of learning that Hattie proposes is quite complicated:
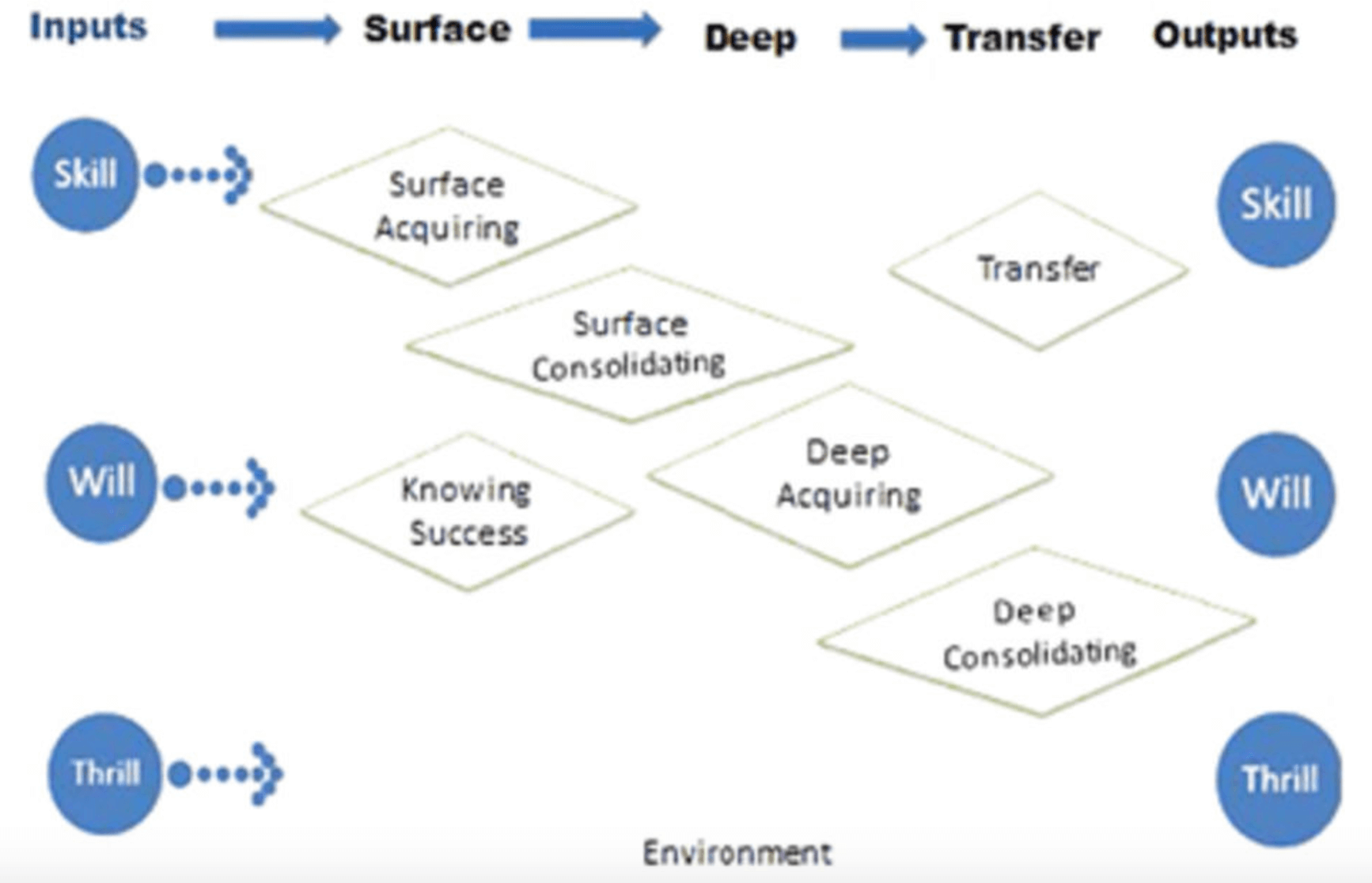
It suggests that for learning to be effective it must take account of three different areas of input that he's termed skill (prior achievement), will (habits of mind) and thrill (motivation). The model relies on Biggs' idea of 'learning processes', which outline three approaches to learning: deep, surface and achieving.
An 'achieving strategy' aims to get the most bang for students' buck: what is the maximum they can achieve with the minimum of effort? A 'surface strategy' to learning is one that aims "to reproduce information and learn the facts and ideas—with little recourse to seeing relations or connections between ideas", whereas a 'deep strategy' that aims "to develop understanding and make sense of what they are learning, and create meaning and make ideas their own." In this model it's fairly clear that whilst achieving and surface strategies might have their uses, a deep strategy is the one we should all be rooting for. After all, who wouldn't want students to make sense of the concepts they encounter and come up with their own ideas?
The idea of depth resurfaces in the 'three phases of learning': surface, deep and transfer. Hattie was very clear that the surface phase isn't any less important than the deep phase, just that it must precede it. The model emphasises "the importance of both surface and deep learning and does not privilege one over the other, but rather insists that both are critical." In order to represent these phases, he uses SOLO taxonomy; 'unistructural' and 'multi-structural' outcomes are superficial, 'relational' outcomes are deep, and 'extended abstract' outcomes are where transfer occurs. I'm not so sure about this. It turned out that Hattie had read my thoughts on SOLO and we managed to find time to have a short discussion, but essentially we left the matter unresolved.
Essentially, my problem is this: knowing and understanding are the same thing. We usually use the word 'understanding' to imply that a thing is known at greater depth but I think 'understanding' actually represents greater breadth: the more you know about a subject, the better you understand it. The fact that you can reverse that statement - the more you understand about a subject the better you know it - just highlights the meaninglessness of using the different words. They are essentially the same thing save that we want to imbue understanding with some mystical, ethereal quality. The application of Occam's razor suggests that there is no need for such a quality when quantity of 'mere' knowledge will suffice.
The problem with depth is that it's a misleading metaphor. It obfuscates the fact that the so-called 'relational' stage of learning (making links and connections between ideas) is something that occurs naturally without any effort on our part. When items of knowledge are stored in long-term memory our brains automatically organises them in relation to each other. If we know two ideas are related, we cannot help but connect them. As we know more about a subject, our schema grows and we become increasingly expert. Expertise is simply a function of practising the application of what we know. The more we know, the better we can think. The more we practice thinking, the more automatic basic applications become, freeing up cognitive resources for more complex applications.
This is where 'transfer' occurs. It's well know that transferring ideas between contexts is much more straight forward for experts than it is for novices and, with that in mind, I suggest that rather than teaching for transfer, we'd be better off teaching for expertise. Anders Ericsson, who's been researching expertise for the last three decades, suggests that we adopt a strategy of purposeful practice which Deans for Impact summarise in this handy graphic:
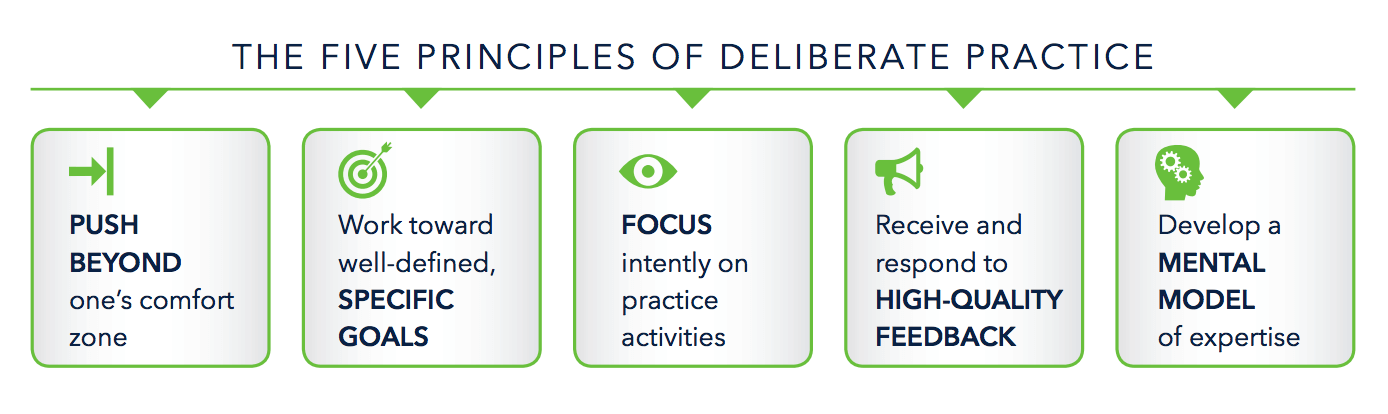 I should say, that (effect sizes aside) I don't see much wrong with Hattie's suggestions for the kinds of strategies teachers and students ought to implement at different stages. My quibble is with the model. If we replace surface→deep→transfer with novice→expert, everything becomes a lot more straightforward.
I should say, that (effect sizes aside) I don't see much wrong with Hattie's suggestions for the kinds of strategies teachers and students ought to implement at different stages. My quibble is with the model. If we replace surface→deep→transfer with novice→expert, everything becomes a lot more straightforward.In my next post I unpick the specifics of research underpinning the model.
The Learning Spy Substack is a sharp, provocative dispatch from the front lines of education, where ideas are tested, myths are challenged, and nothing is taken for granted.
Join me on Substack