Why using the curriculum as your progression model is incompatible with 'measuring progress'
Sep 11, 2021
Our capacity to misunderstand complex ideas leads, inexorably, to the lethal mutation of those ides. In my last post I set out why the apparently simple and obvious notion of 'using the curriculum as a progression model' often goes wrong but I underplayed some key points about the use of numbers. Tucked away in that post are two ideas that need some amplification and explanation.Firstly, in relation to the way in which summative assessments are scored:
I should note that the key assumption underpinning this assessment model is not that tests should discriminate between students so we can place them in rank orders and assign summative statements of progression. Instead, in order to ensure progression through the curriculum, these tests should be primarily seen as statements of competence, that students have mastered the content sufficiently well to progress.If we using the curriculum as our progression model all we need to know is, how well students have learned this aspect of the curriculum. Whilst the purpose of a GCSE exam is to say how well students have performed relative to one another, the purpose of a test attempting to assess how much of the curriculum has been learned should not be interested in discriminating between students. Ideally, if the curriculum is perfectly specified and taught, all students would get close to 100%. Clearly, we'll never come near this state of perfection so if we achieve average scores of about 80% we should be well satisfied that we are specifying and teaching incredibly well.
Over the long term, if students fail to meet a threshold of confidence the assumption should be that there is a fault either with the design of the curriculum or in its teaching. In the short term, if a minority of students fail to reach the threshold this leaves us with the 2 sigma problem Benjamin Bloom failed to solve: how can we scale the time and resources required for all students to be successful? The best I'm currently able to suggest is that we need to have specified and sequenced our curriculum to focus heavily on the most crucial concepts within subject disciplines and to ensure these at least are mastered. If our guiding assumption was that any test score below 80% highlighted some fault in specification or instruction, this could transform the educational experiences of our most disadvantaged students.
We can't measure progress, only performance
The second point made in the previous post that I want to return to was on what we should avoid doing with numbers:
What we can’t do is compare the percentage a students gets in Term 1 with one achieved in Term 6 and attempt to draw a line between them indicating progress. This would assume that the second test was objectively more difficult and that if the numbers go up, then progress is being made. We may believe this to be true but it’s very rare to find schools that have put the effort into calculating the difficulty of test questions required to make this a defensible claim.In order to explain what I mean, I need to take you back to Becky Allen's 2018 blog, What if we cannot measure pupil progress? In it she said,
The key to using numbers sensibly in this model is to only to compare across space (laterally) and not across time (longitudinally). What I mean by this is that it makes perfect sense to compare how different students, classes or cohorts have performed on the same assessment, but not to compare the results of different assessments.
When we use ... tests to measure relative progress, we often look to see whether a student has moved up (good) or down (bad) the bell curve. On the face of it this looks like they’ve made good progress, and learnt more than similar students over the course of the year. However [the test] is a noisy measure of what they knew at the start [and] the end of the year. Neither test is reliable enough to say if this individual pupil’s progress is actually better or worse than should be expected, given their starting point.Tests are very useful for assessing how well students have learning particular curriculum content but cannot be used to measure the rate at which students are progressing towards better future test performance. Just because a student has learned a lot about, say, the Norman Invasion or Buddhism, we cannot claim that they will do equally well (or better) on a test of the Tudors or Hinduism. And if they do less well on a subsequent test we cannot claim that students are making negative progress. What we can - and should - perceive is that they don't know some aspects of the curriculum as well as others, and intervene accordingly.
This is what I meant about lateral rather than longitudinal comparison. It's not only possible but desirable to compare how different students perform on same assessment. If my class performs much worse than yours on the same assessment could infer either that students in your class are, on average, clever than those in mine, or that you have taught the curriculum better. While the first inference may be true, it is not useful. 'Top sets' are routinely filled with students from more affluent backgrounds who are often successful despite rather than because of the choices we make. Rather than worrying about ability, We might do better to track indices of social disadvantage: if our more disadvantaged students are doing well we can be reasonably sure this is due to how well we've specified and taught the curriculum. It might be useful to only use these pupils when analysing test data.
Longitudinal comparison, or attempting to measure progress, is fraught with error. Even if we don't make the lamentably common mistake of assessing students ability to do thing we haven't actually taught them, the test students sit will only sample from the domain of what they were taught. How students perform in that test give us some sense of how well an individual student has learned the curriculum relative to their peers but it's only by establishing a scalogram of student performance vs item difficulty that we will get a sense of what individual test score might mean. As I said in this post,
Typically, we just see a test as a mechanism for measuring students’ ability, or level of development, and fail to understand that getting 50% in a harder test might actually be better than getting 70% in an easier test. But we should also understand that if one student gets 70% and another gets 35% on the same test, that does not mean the first student has done twice as well as the second student. It should be obvious that getting less than 35% is far easier than getting more than 35% and, if a test is well designed, items will get progressively more difficult so as to better measure individual students’ performance.Here's an example of a scalogram that compares students' performance against item difficulty:
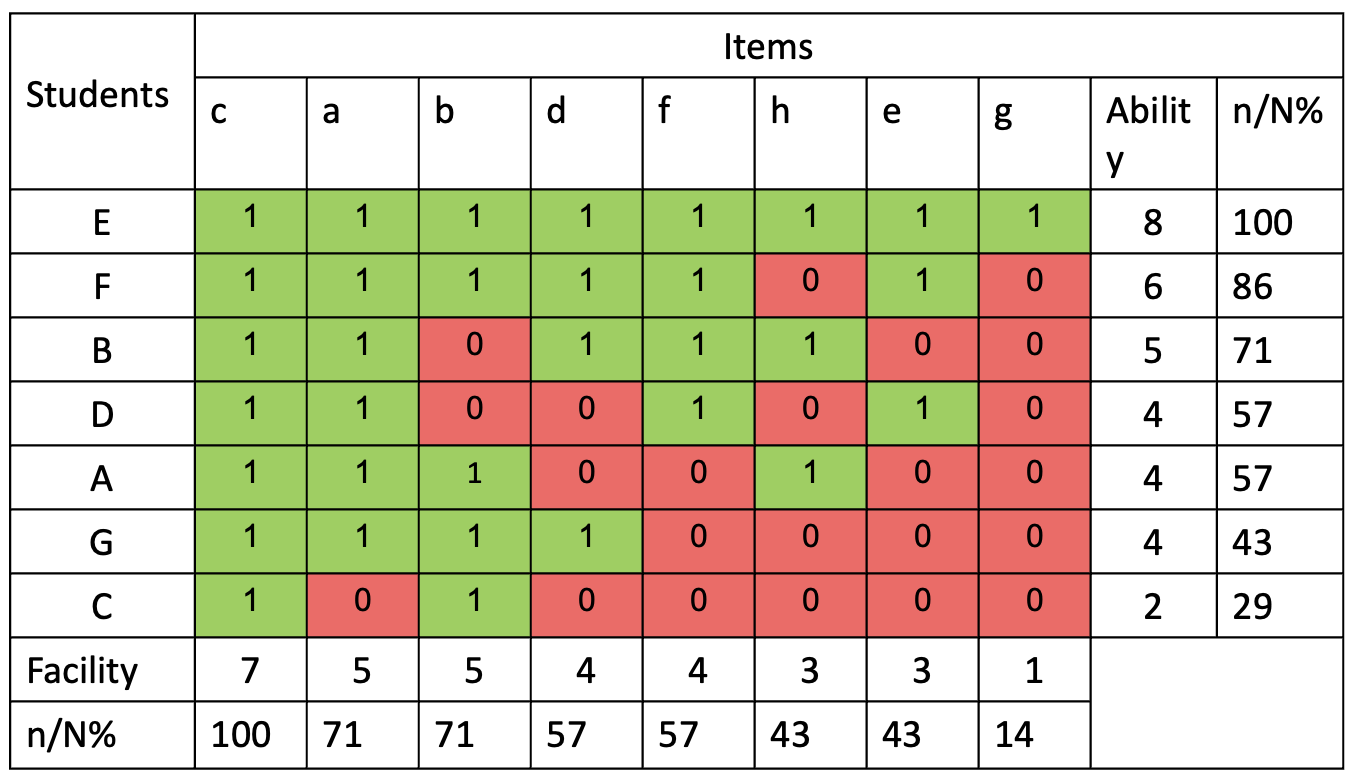
I should explain that item difficulty is established by working out which questions students answer correctly; the more students answer an item correctly, the easier that item is, and the fewer students answer an item, the harder it is. So, we can see in the table above that although students A, D, and G all achieved the same test score, Student D was able to answer more difficult questions than Students A and G.* One explanation could be that Student D had not been present in class when some of the content most students found easy to answer was taught. Or, similarly, it could be that Student G missed some of the later curriculum content. Either way, the test score tells us relatively little about these students' ability to make future progress but quite a lot about what they have learned to date. It ought to be clear that we should not intervene with these three students in the same ways. And, I hope, it ought to be equally obvious why drawing a line between performance in two different tests is likely to tell us little of any use about students' progress.
*
I hope this additional explanation makes sense and proves useful. If you have further questions or would like to point out errors in my thinking I'd be most grateful to hear from you.* There’s a discussion to be had here about whether the marks awarded to an item should only be decided after a test has been taken and item difficulty is established. By marking each question equally we are likely to obscure students’ actual performance.
The Learning Spy Substack is a sharp, provocative dispatch from the front lines of education, where ideas are tested, myths are challenged, and nothing is taken for granted.
Join me on Substack