Proof of progress Part 2
Mar 11, 2016
Back in January I described the comparative judgement trial that we were undertaking at Swindon Academy in collaboration with Chris Wheadon and his shiny, new Proof of Progress system.Today, Chris met with our KS2 team and several brave volunteers from the secondary English faculty to judge the completed scripts our Year 5 students had written. Chris began proceedings by briefly describing the process and explaining that we should aim to make a judgements every 20 seconds or so. The process really couldn't be simpler: the system displays two scripts at a time and you just have to judge which one you think is best.

[caption id="attachment_9370" align="alignleft" width="300"]
 Teachers judging as Chris looks on[/caption]
Teachers judging as Chris looks on[/caption]When you've made your decision, you simply click either the Left or the Right button and the next two scripts are presented. It's as simple as that.
We had 97 candidates' scripts to judge, 27 judges and we took a grand total of 7 minutes to arrive at an extremely reliable rank order. When essays are marked by trained examiners using a mark scheme they typically achieve a reliability of between 0.6 - 0.7. We managed a reliability score of 0.91! What this means is that if anyone else were to place our scripts in a rank order there's a very high probability that they'd arrive at the same order.
Here are the scores for our 10 top ranked scripts:
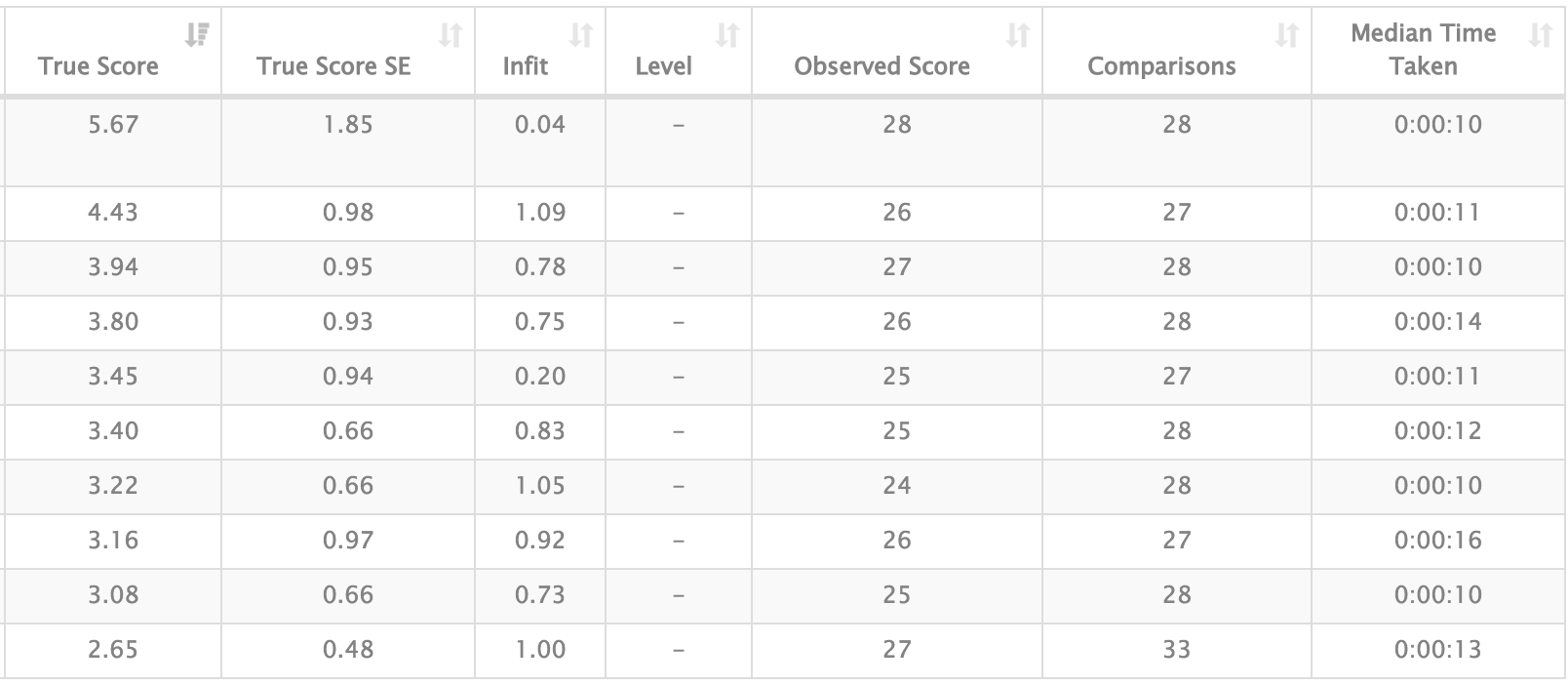
And our 10 lowest placed scripts:
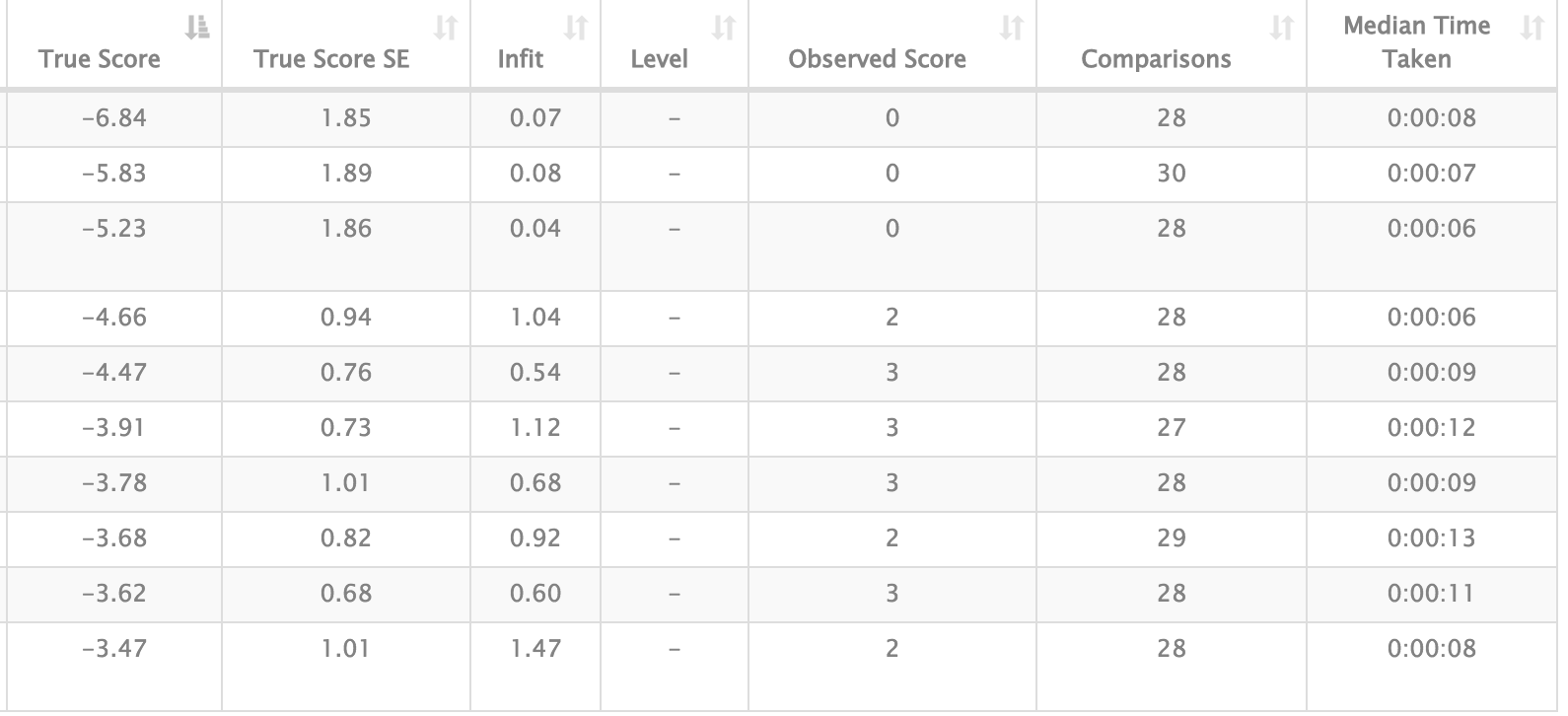
Here are our best and worst writers:

We then wanted to decide what the cut off point for 'age related expectation' for writing in Year 5. The consensus was 'about 50%' of the students were currently meeting an acceptable standard, so we looked at a couple of the scripts at the halfway point to determine whether they did indeed represent a reasonable standard of writing:

What do you think? While we'd been judging our conversations were perfectly amicable and our decisions were consensual. As soon as we started discussing standards, no one could agree. This goes to show the impossibility of making holistic judgements. In the end, Chris said, "What do you think?" If a majority of us said either yes or were unsure, that should be out cut off point. In the end it was as straightforward, and as mysterious, as that. As Chris said, "If you think it's around there, it's there." The standard becomes the actual work rather than some arbitrary verbiage in a rubric.
This might seem unsatisfying for teachers raised on the perceived objectivity of standards enshrined in rubrics, but it really is as accurate a way of determining a cut off as anything else. Chris explained that exam boards always start with the numbers, then they look at the candidates’ work for confirmation that the numbers are about right
So, now we knew, with a reliability of over 90%, how many and exactly which of our students were performing at a standard we deemed acceptable. In terms of the simplicity and expediency of the process, everyone was happy, but what next? How could we judge whether our students were making progress?
This is easier than you might think: you simply take a sample of scripts for which you've already agreed a score and then include these known quantities in a second assessment to use as an anchor. Then, when you judge this second set of scripts you already know the value of some and all the other scripts can then be judged either better or worse. You then compared the 'true' scores for students in both assessment rounds and measure the change.

In this way, you can arrive at a much more reliable measure of progress than is ever achieved by external exams and vastly better than that possible with teacher assessment. As a school, if the trend for a majority of children is upwards, that's a fairly cast iron indication that progress is being made. If the trend is downward, that's essential feedback on the quality of teaching! Our plan is to repeat this process in the summer term to measure how the performance of these children is (hopefully) improving.
But what about feedback? One of the criticisms of the process is that it's all very well for making summative judgements, but how will it help students improve? Firstly, teachers taking feedback from students is as, if nor more, important then students being given feedback. Finding out how effective our instruction is pretty important and this gives us some very useful information on how well students are performing. Secondly, we now have some very useful tools to feedback to students about what good looks like and some benchmarks to measure themselves against. We're planning to get students to go through a ranking exercise themselves so that can get a sense of the varying quality and the associated features of their peers' work. This sets us up to be able to give precise, meaningful feedback to individuals on exactly what they need to do to improve.
We also got feedback on the accuracy of individual judges' performance:
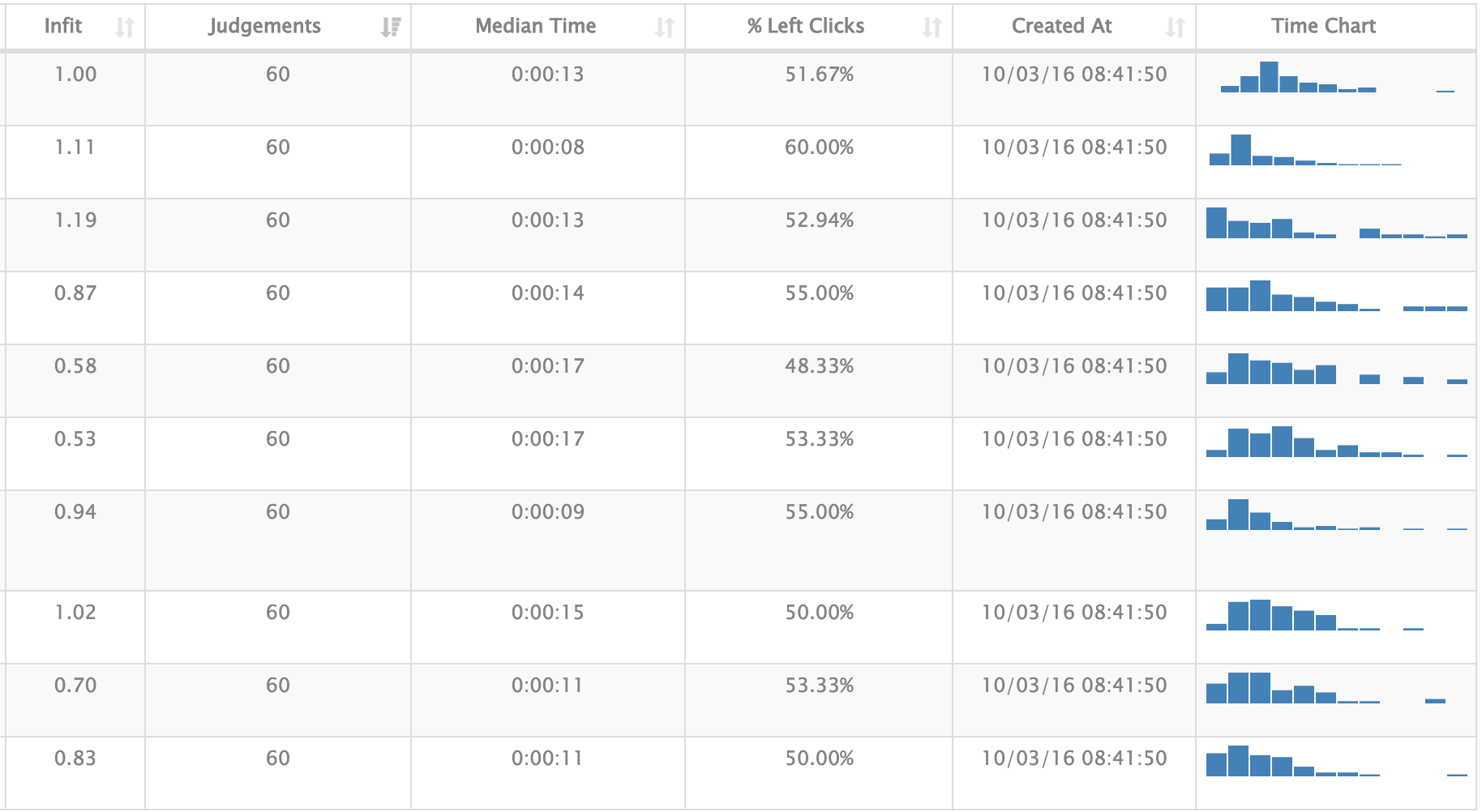
Chris explained that the lower the infit score, the better, but that anywhere between 0.5 - 1.5 is fine. Infit is short for inlier-sensitive or information-weighted fit. and is a measure of consistency. Infit values of 1 or below represent high consistency. Infit values of above 1.2 suggest inconsistency, possibly due to carelessness. Chris also told us that, "There’s no dishonour in being a bad judge" - like anything else, this is something we improve at with experience. (If you're interested, I came out with an infit of 0.69, a median time of 7 seconds and made 49.06% left clicks.)
The only concern that came from our teachers was the possibility that children might be penalised for poor handwriting. Chris told us that when they first started analysing their results they thought they were detecting a gender bias as boys were being consistently ranked lower than girls. When they typed up a sample of answers and put them in for further judging, the gender bias disappeared. What they had detected was actually a handwriting bias. Boys, on the whole, have messier hand writing than girls.
Maybe this simple fact might account for gender gap in national exams? If so, it could be relatively simple to solve. I doubt whether boys' messy handwriting is a function of their biology; it seems much likelier to be a cultural artefact. That being the case, surely to goodness we can teach boys to improve the way the hold a pen and neaten up their writing?
Our next step is to compare our rank order with that of students studying for PhDs in creative writing. My suspicion is that teachers' judgements might be warped by the long habit of relying on rubrics to assess students' work. All too often we end up teaching what's on the rubric and missing out on other features of expert performance. We end up rewarding work which meets the mark scheme's criteria even if we think it's a bit ropey. Likewise, some students are penalised because although they write well, their work doesn't obviously display the features a marker is primed to look for. It will be fascinating to see whether a different kind of 'expert' arrives at a different judgement.
I'll fill you in on the details in Part 3.
The Learning Spy Substack is a sharp, provocative dispatch from the front lines of education, where ideas are tested, myths are challenged, and nothing is taken for granted.
Join me on Substack